فهم الترميز (Encoding) وهجمات Homograph وHomoglyph: دليل شامل
في المقالة دي، هنفهم إيه هو الترميز، أنواعه، وإزاي بيُستخدم في هجمات الـ Phishing زي Homograph وHomoglyph. مع أمثلة عملية ونصائح أمان.

بسم الله الرحمن الرحيم
اللهم لا علم لنا إلا ما علمتنا إنك أنت العليم الخبير
من فترة انتشر بوستات كتير عن شخص عامل Domain بيستخدموه في الـPhishing وعمل الدومين على شكل rnicrosoft عشان يبان أكانها microsoft ولكنها مكتوبة r+n ..
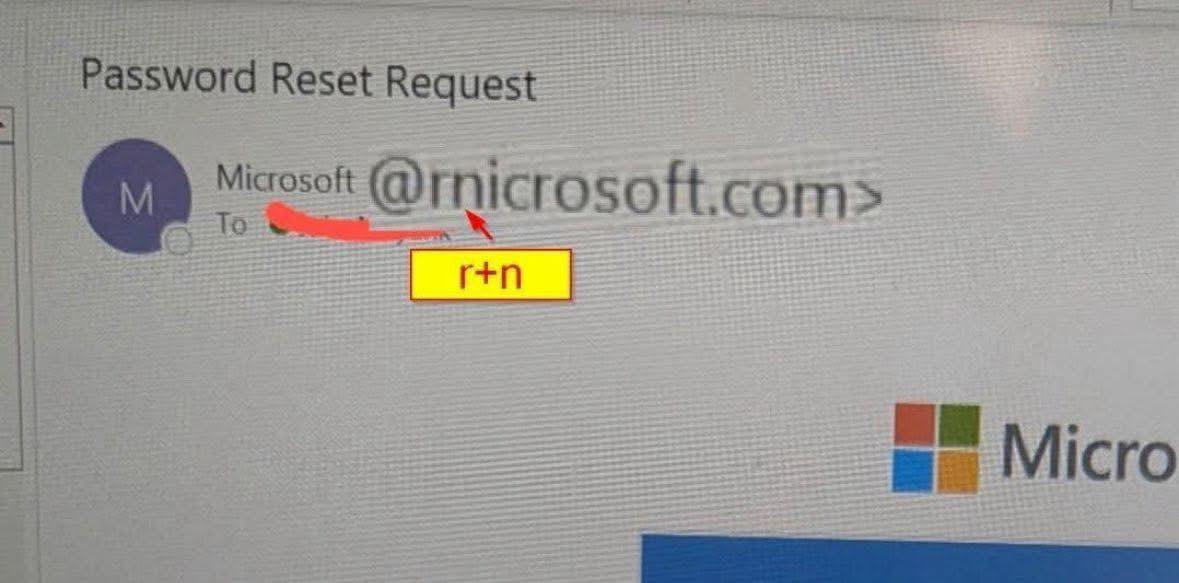
ودا Technique قديم وشائع جدًا في الـPhishing attacks إسمه Homograph attack ..
فـ حبيت أتكلم عن الـHomograph وHomoglyph attack في المقالة دي بالتفاصيل حتى تضمن عزيزي القارئ قراءة مُمتعة بعون الله وفضله..
ولكن قبل ما أتكلم عن الـTechnique دا، حابب أشرح يعني إيه Encoding وأنواعه لتسهيل فهم الـHomograph attacks .. ودي اللمفاهيم اللي هتفهمها بإذن الله بعد قرايتك للمقالة دي:
- Encoding
- URL Encoding
- HTML Encoding
- BASE64
- ASCII and Extended ASCII
- Unicode
- Unicode style (UTFs)
- Homograph Attack
- Homoglyph Attack
- Web Server Encoding
إيه هو الـEncoding؟
الـEncoding أو الترميز هي تحويل صيغة نصية أو رقمية لصيغة أخرى مختلفة عنها في الشكل، ودا بسبب إن الداتا بتتعامل مع أكتر من سيستم في نفس الوقت (نظام تشغيل، قاعدة بيانات، سيرفرات، بروتوكولات) وكل سيستم بيقرأ الداتا بطريقته، وبالتالي لازم يحصل تغيير في الداتا بما يناسب كل سيستم الداتا بتتعرضله.
إذن الـEncoding هو طرق مختلفة لعرض نفس البيانات ولكن بأكثر من شكل..
وبالتالي كل شكل من أشكال الـEncoding بيناسب سيستم مُعين.
وهنا ظهر عندنا أنواع للـEncoding بتكون معروفة وعالمية (standard).
وطبعًا أي داتا بيتم عمل لها encoding، الخوارزمية اللي مُتبعة في تحويل شكل الداتا بتكون معروفة، وبالتالي سهل جدًا يتعملها decoding بمجرد معرفة الخوارزمية أو نوع الـEncoding!
وعشان كدا مش بيتم استخدام الـEncoding لغرض التشفير، عكس الـEncryption methods اللي هي اللي بتستخدم لكدا..
ومن أشهر أنواع الـEncoding هي:
- URL Encoding
- HTML Encoding
- Base64 Encoding
- Unicode encoding
وفيه أنواع تانية بس دول أشهرهم…
أولاً: URL Encoding
الـURL اللي احنا بنقوم بكتابته في المتصفح زي
www.google.com/page?parameter=value
دلوقتي في الـURL دا، أنا هروح على موقع جوجل على صفحة اسمها page.
طب دلوقتي لو اسم الصفحة مش page وكان عند جوجل اسمها مثلًا page 2، وطبعًا هنا الإسم فيه مسافة، وبـ كدا المسافة دي مينفعش تظهر في الـURL بشكلها الطبيعي لإن مفيش مسافات أصلاً في الـURLs لإن المتصفح هيفسر المسافة دي كفاصل أصلاً …
فـ هنا هنعمل URL encoding بحيث نحول المسافة دي لشكل تاني، وهو تحويل المسافة إلى URL Encoding Character كما في الصورة الأتية:
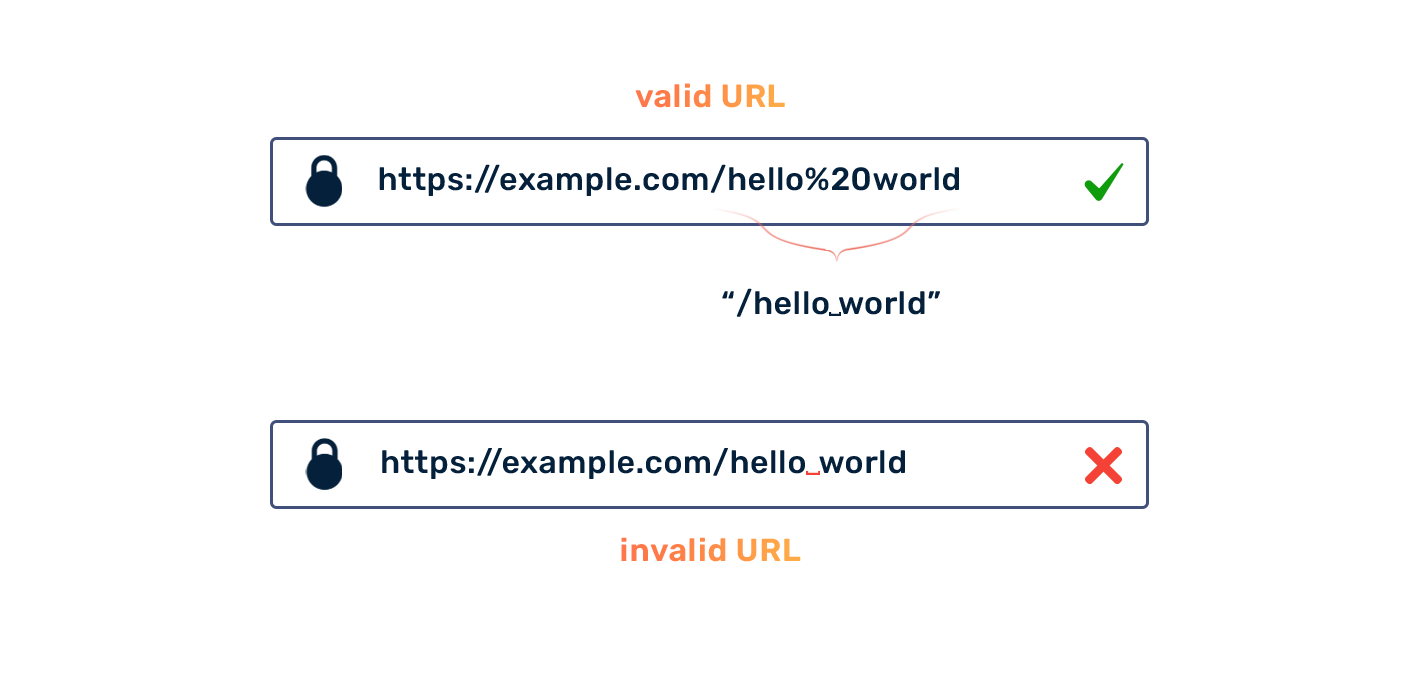
وهنا تم تحويل المسافة إلى %20، وتقدر تشوف تحويلات كل الحروف والأرقام والـspecial characters من خلال الرابط التالي: W3Schools URL Encode
أمثلة على URL Encoding:
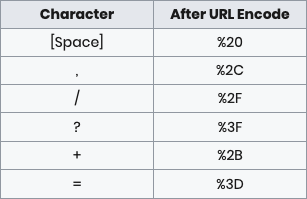
- المسافة (
%20 - علامة الـ
=→%3D - علامة الـ
/→%2F - علامة الـ
#→%23 - علامة الـ
?→%3F - علامة الـ
&→%24 - علامة الـ
%→%25 - علامة الـ
+→%2B
وطبعًا بيتم استخدام الـURL Encoding:
1- عشان الرابط يشتغل صح على كل المتصفحات.
2- الحماية من بعض الـattacks اللي بتحصل على مستوى الويب أبليكشن.
HTML Encoding
الـ HTML Encoding بيتم استخدامه عشان لو عايز تعرض نص في صفحة ويب بس من غير ما المتصفح يعتبره كود بل يتعامل معاه كنص. يعني لو اليوزر كتب <script> في input بيتم عرضه على صفحة الويب الخاصة بيك، من غير HTML Encoding، الصفحة هتحاول تنفذه ككود، وده خطر. فبنستخدم الـHTML Encoding ..
وزي ما موضح في صورة التالية، مجرد سكريبت بياخد input وبيعرضه مرتين: أول مرة بدون HTML Encoding، وتاني مرة بـHTML Encoding عشان تفهم الفرق:
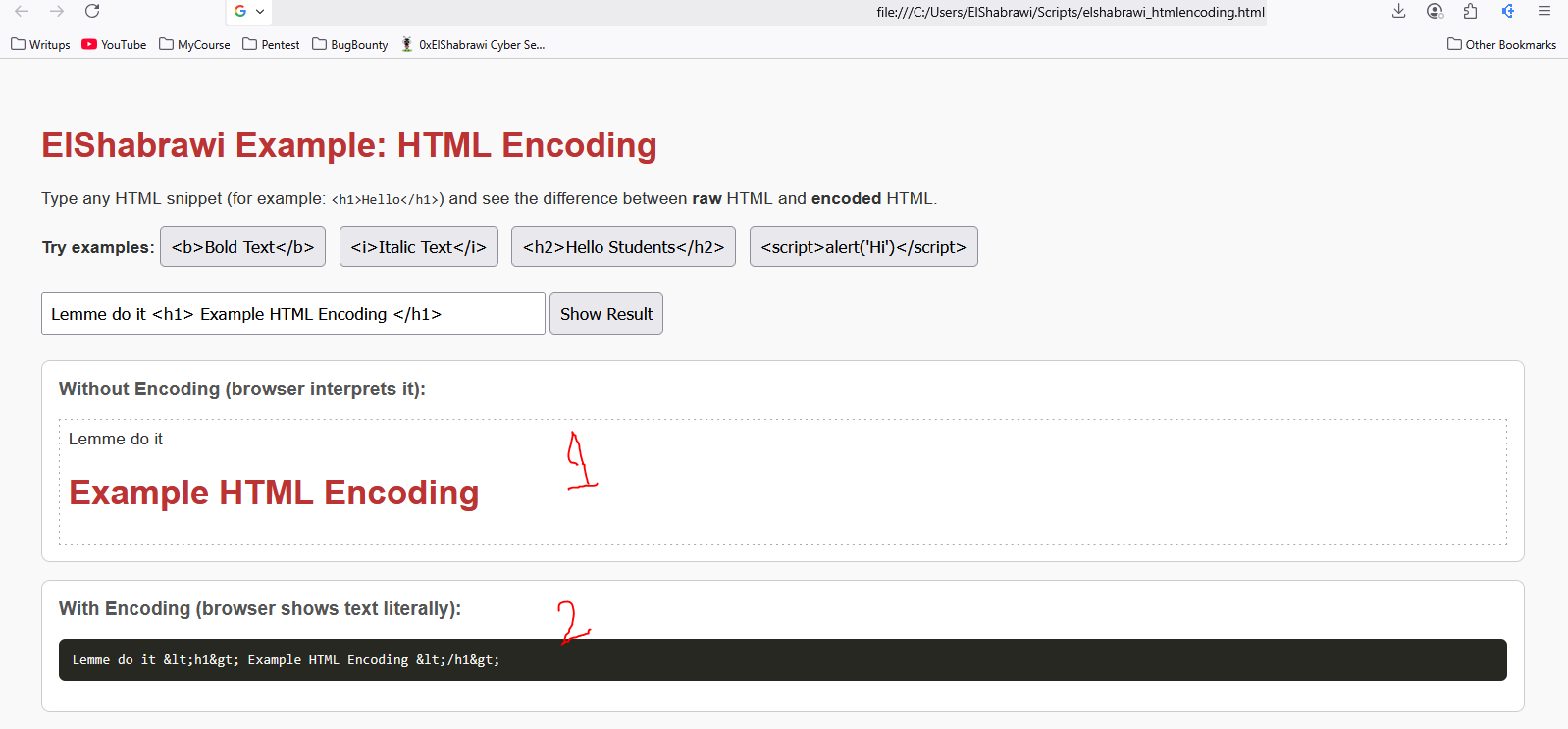
اليوزر قام بإدخال: Lemme do it <h1> Example HTML Encoding </h1>
أول مرة اتعرضت بدون HTML encoding، وبالتالي صفحة الويب قرت تاج الـ<h1> وحصل هنا HTML injection ..
ولكن تاني مرة، اتعرضت الكود اتحول لـLemme do it <h1> Example HTML Encoding </h1>
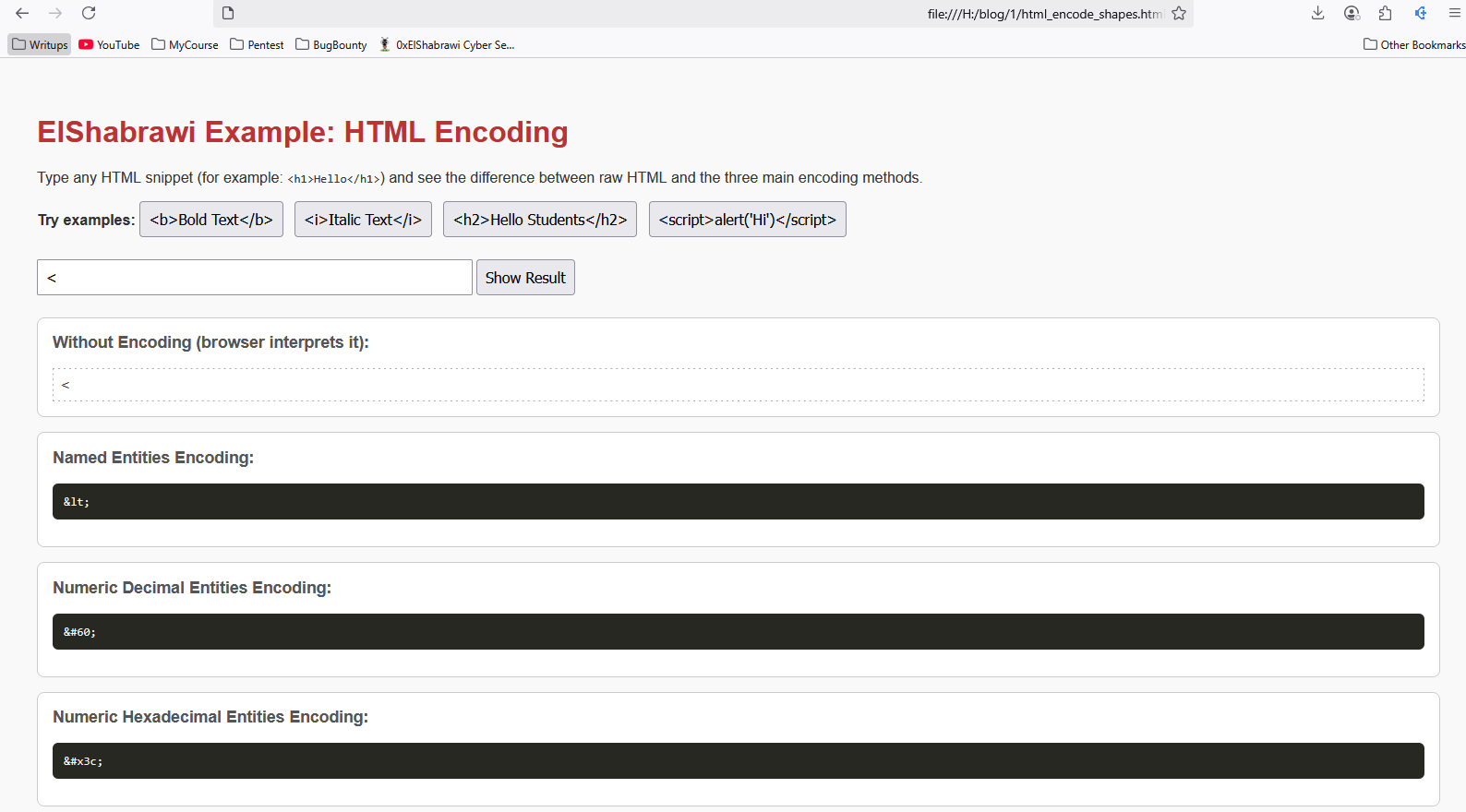
ودا بالظبط شكل حروف الـHTML Encoding، وممكن يتم عمل الـencoding دا بـ3 طرق، وكل طريقة بتختلف في شكلها فقط مش أكتر، والصورة اللي تحت هتوريك شكل كل واحدة فيهم .. ألا وهُما:
- Named Entity: هنا بيتم تحويل الحرف لـnamed entity سهل القراءة.
- Numeric Decimal Entity: هنا بيتم تحويل الحرف لـ أرقام عشرية يسبقها
&#. - Numeric Hexadecimal Entity: هنا بيتم تحويل الحرف لـ هيكساديسمال يسبقها
&#x.
وهنظهر الفرق بين كل واحدة في الصورة دي، مثال لعمل HTML Encoding لـ >:
Base64
الـ Base64 هو نوع Encoding بيقوم بتحويل الداتا – حتى لو كانت صور أو ملفات – لنص عادي عشان يتنقل بسهولة بين الأنظمة. بيستخدم 64 حرف بس: [A-Z], [a-z], [0-9], +, /, و=.
على سبيل المثال، أنا قبل كدا كنت بقوم بإستخراج داتا من قاعدة بيانات من خلال SQL Injection، وكان فيه صور موجودة وعايز أطلعها ضمن البيانات دي وأحطها على sheet Excel، ومعرفتش أطلع الصور دي إلا من خلال تحويل كل صورة من صورة لـBase64 text عشان أقدر أسحبها وأعملها save داخل شيت الإكسيل دا..
إزاي بيشتغل؟
مثلًا لو عايزين نعمل encoding لكلمة Yasser، أول حاجة هنحولها لـBinary:
01011001 01100001 01110011 01110011 01100101 01110010
فـ طبيعي هنا كل حرف بيكون 8 بتات زي فوق كدا..
الـBase64 لما بتشتغل بقى بتقسمهم لـ6 بتات فقط، وبالتالي هتبقى كدا:
010110 010110 000101 110011 011100 110110 010101 110010
نرجع بقى نحول الـbinary بعد ما قسمناه 6 بتات فقط لـText، وهو دا هيكون الـBase64.
مثال:
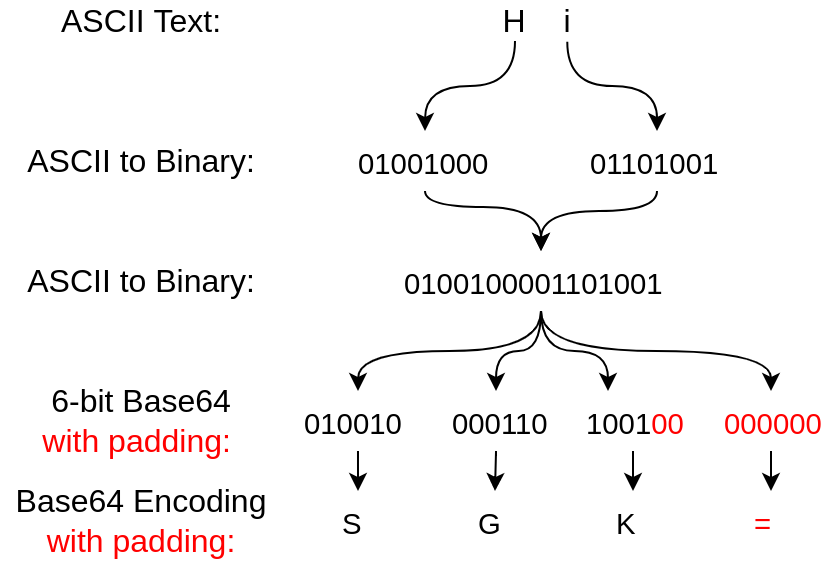
وغالبًا ما بيتم استخدامه لأجل نقل البيانات من خلال الـAPIs أو تخزين البيانات في صيغة نصية ..
ASCII Character Set and Extended ASCII
تمام، هنتكلم دلوقتي عن الـASCII وExtended ASCII وإيه الحدوتة بتاعتهم ..
معروف إن الكمبيوتر مش بيفهم غير الصفار والحوايد Zeros & ones (binary)، وإنه لا بيفهم اللغة العربية ولا اللغة الإنجليزية وكدا ..
فـ احنا كنا عايزين حاجة تكون حلقة وصل ما بين الـbinary اللي الكمبيوتر بيفهمه والحروف اللي احنا بنفهمها.. وجاء من هُنا اختراع الـASCII Character set ..
الـASCII Character Set يعتبر ربط ما بين الحروف بتاعتنا بالأرقام الـbinary بحيث يفهمها الكمبيوتر، فـ كل حرف في الكيبورد بيكون له ASCII Number خاص به، بحيث الكمبيوتر أول ما يشوف أي حرف غريب عليه يحوله للـASCII Number الخاصه بيه بحيث يقدر يتعامل مع الحرف دا ويعرفه..
ودا شكل الـASCII Character set table اللي بيحتوي على الحروف كلها وهما الـ127 حرف.
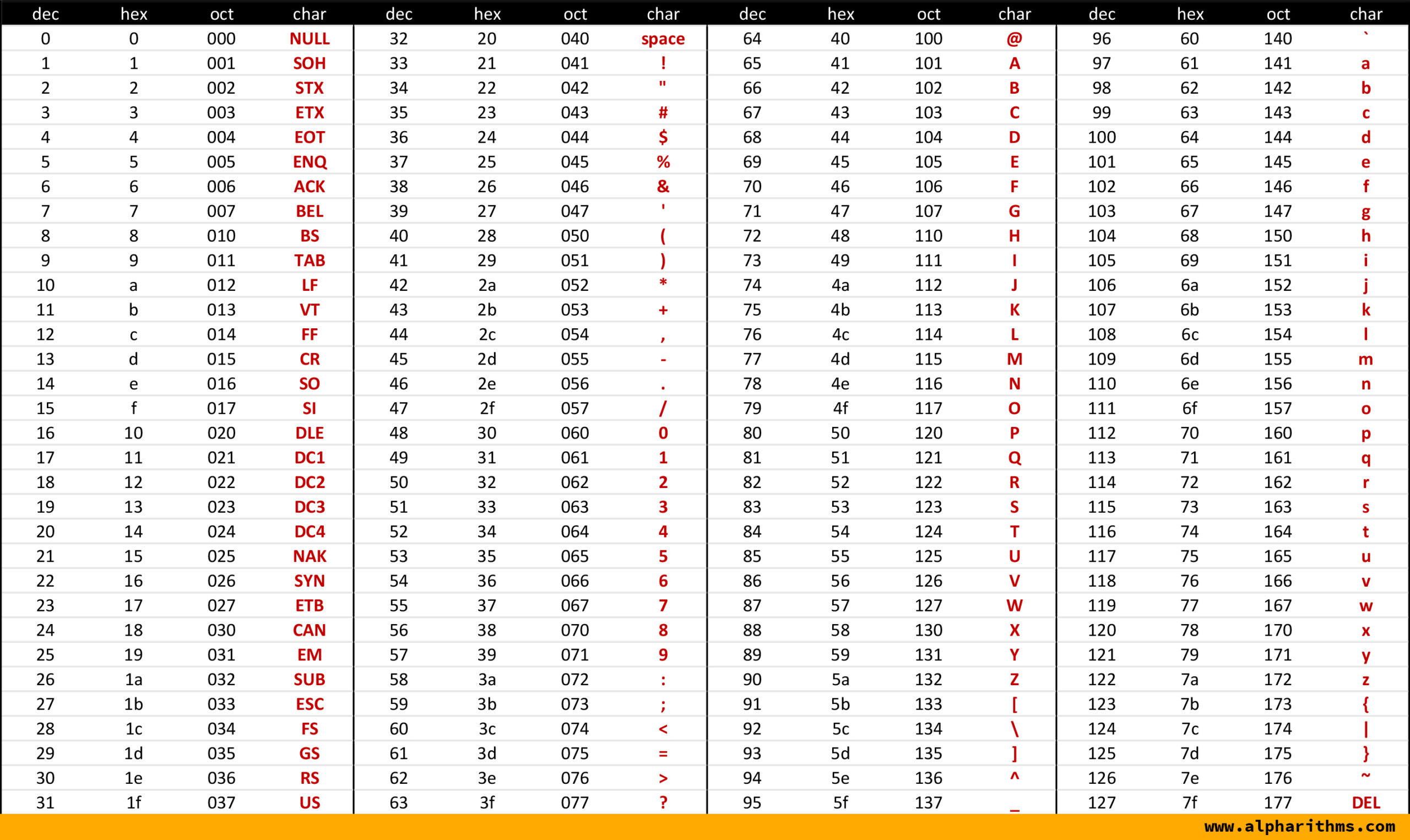
الرقم decimal اللي هو أول رقم ع شمال دا هو رقم الحرف كـASCII character set ..
بس خلينا نسأل سؤال مهم منطقي ..
عدد الحروف مثلاً في لغة العربية والإنجليزية أكبر من 127 حرف، ازاي والـASCII فيه 127 حرف فقط!
هقولك سؤال عبقري من شخص عبقري زيك.. فعلًا الـASCII دا كان أخره يشيل الحروف الإنجليزي كابيتال وسمول والأرقام وشوية special chars زي ما واضح في صورة..
وبالتالي عملوا حاجة إسمها Extended ASCII Characters، ودي بتشيل لحد 255 حرف من 128 لـ 255.. ودا كويس جدًا بحيث إنه الـExtended ASCII Characters دي تكون لأي لغة تانية عايزها بقى زي العربية أو الصينية أو أي لغة تانية.. ولكن دا مكانش كافي ولقيوا إن فيه لغات بتحتاج عدد أكبر من كدا.. طب والحل؟
هنعرف الحل بس خلينا نعرف معلومة كدا ع سريع الأول، اللي هي إجابة السؤال التالي:
طب ليه الـASCII بيشيل 127 ؟ ولما خلوه Extended بقى بيشيل 255 ؟
دا لإن الـASCII فالأول كانت بتتكون من 7 bits، يعني الحرف الواحد أخره يكون حجمه من 1 بت لـ 7 بت، يعني من
0000000
لـ
0111111
وكدا الأرقام مثلًا لما نيجي نمثلها بالـbinary:
0 = 00000000
1 = 00000001
2 = 00000010
3 = 00000011
وفيه قاعدة رياضية ثابتة بتقول عشان تعرف عدد الاحتمالات اللي ممكن تطلعلك من الـbits دي هو:
2 ^ عدد البتات = عدد الإحتمالات، بالتالي 2 ^ 7 هتساوي معانا 128.
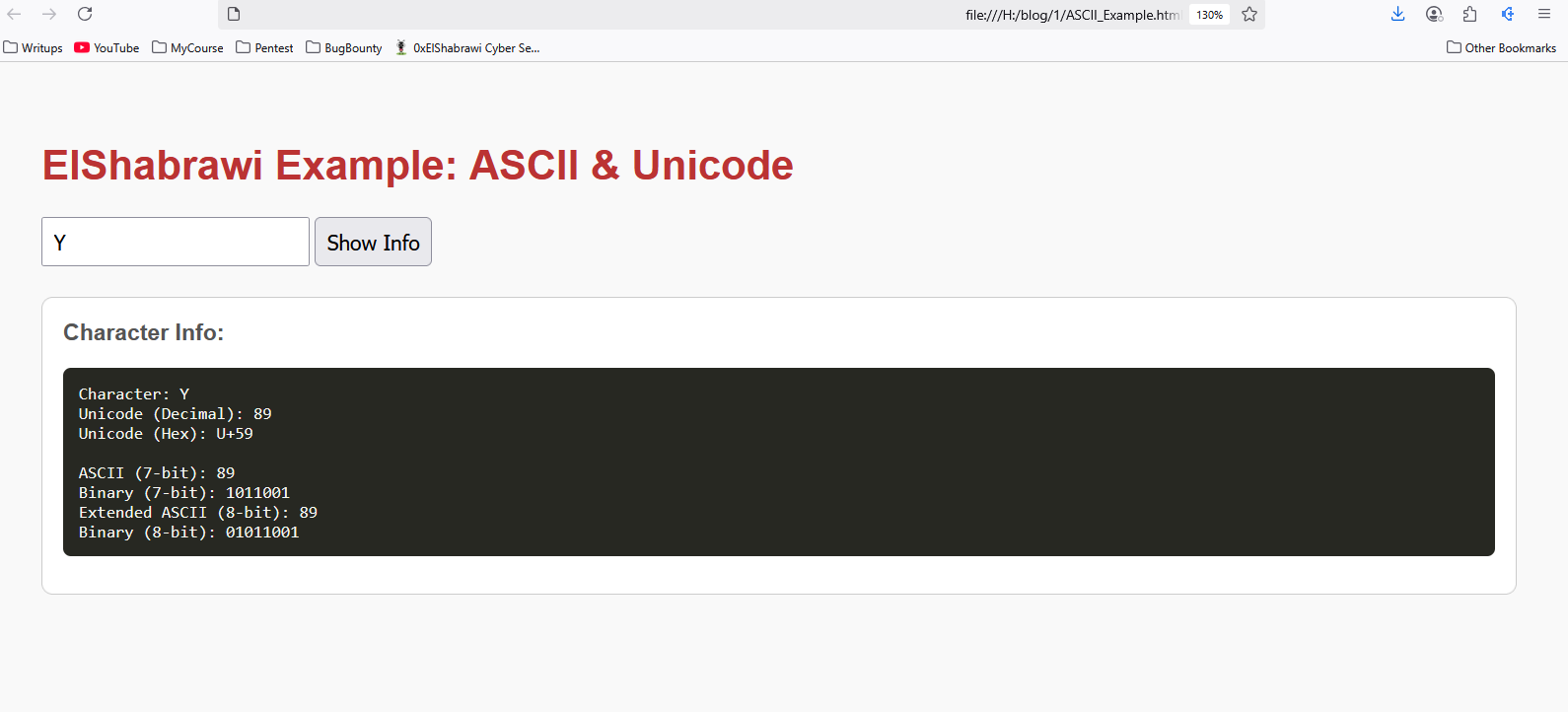
ولما عملوا Extended ASCII قالوا إحنا هنخلي الحرف يتكون من byte كاملة، يعني 8 بتات:
من
00000000
لـ
11111111
وبالتالي 2 ^ 8 هتساوي 256، ودي أسباب إن الـASCII والـASCII Table هتتكون من العدد دا فقط من الأحرف..
ولكن لما لقيوا إن عدد الأحرف دي مش كفاية وفيه لغات تانية بتحتاج عدد أكبر من الحروف.. قرروا إنهم يستغنوا عن الـASCII ويتم إستخدام الـUnicode.
الـUnicode
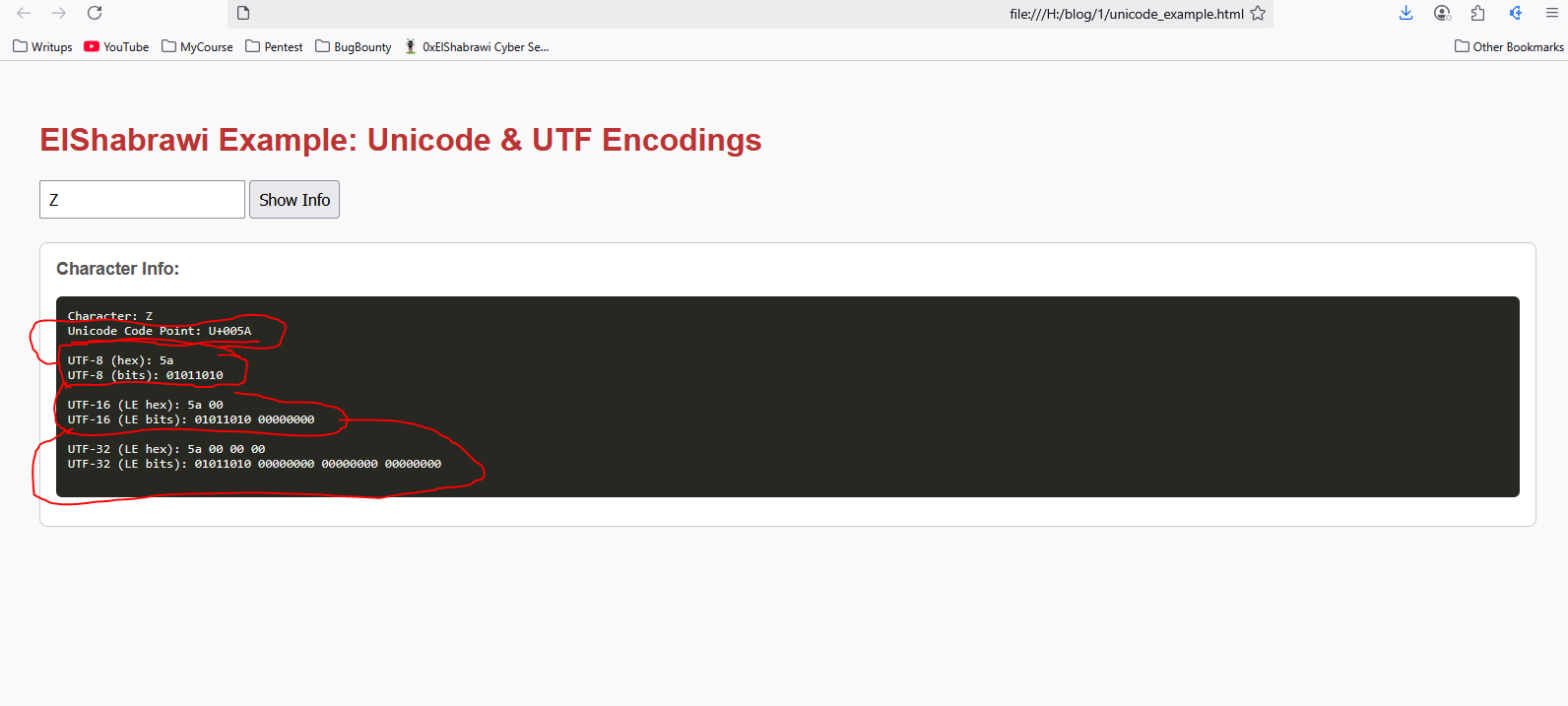
الـUnicode في الأساس جه عشان يحل مشكلة الـASCII اللي مكانش بيدعم كل اللغات.. الـUnicode دا بقى بيدي كل حرف في العالم حرفيًا Code Point، شكله بيكون كدا U+XXXX.
مثلًا:
- حرف الـ “س”
U+0633 - حرف الـ “P”
U+0050 - حتى الإيموجي دا “😊” هيبقى
U+1F60A
حرفيًا الـUnicode بيدعم أكتر من مليون code، فهو بيشمل كل اللغات ورموز، بس عشان الكود دا يتعرف من خلال الكمبيوتر ويتخزن، لازم نستخدم “الترميز الخاص به” (Encoding charset)، اللي هي:
- UTF-8
- UTF-16
- UTF-32
الفرق بينهم في الرقم دا اللي بيعود لعدد الـbits المستخدمة للحرف الواحد. مثلًا لغة زي الصينية ممكن الحرف الواحد على سبيل المثال فقط يكون بيستخدم 10 bits، يبقى كدا أنا هحتاج أستخدم الـUnicode UTF-16 عشان بيستخدم 16 بت والحرف بيعوز 10 بتات فـ هيكفي الحرف وزيادة، ومش هينفع UTF-8 عشان بيستخدم 8 بتات والحرف عايز 10 بتات..
بس اللي قولته دلوقتي دا كان لتسهيل الشرح، اللي بيحصل بالفعل إنه الـUTF-8 ممكن يستخدم 1 بايت أو 2 بايت أو 3 بايت أو 4 بايت حسب احتياج الحرف، لكن الـUTF-32 بيجبرك تستخدم 4 بايت لكل حرف.. (البايت الواحدة بتساوي 8 بتات).
الـUTF-8 هو أشهر نوع فيهم وبيكون مناسب أكثر للويب وسيرفرات لإنه بيدعم كل الحروف ورموز من العربي والإنجليزي والإيموجي، وبيوفر مساحة لإنه بيستخدم 8 بت فقط للحروف العادية زي اللغة الإنجليزية..
وأخيرًا: Homograph & Homoglyph Attack
كل اللي فوق دا عشان نفهم الكام كلمة اللي جايين، فـ رجاء لو مش فاهم أي سطر من كلامي فوق، اطلع اقراه وتعالا تاني..
احنا فهمنا إن في عالم الـcomputing، النصوص اللي ظاهرة قدامنا بكل أنواعها مش مجرد نصوص ظاهرة، بل هي في الأصل أصفار وواحد، وبتتحول لأرقام وأكواد وشغلة كبيرة كدا عشان الكمبيوتر يفهمها واحنا نفهمها..
وطبعًا إخواننا الـهكرز حبايبنا فكروا في فكرة حلوة أوي ألا وهي: إنه ليه منخليش النصوص دي تبقى خادعة؟ سواء عن طريق التشابه البصري، يعني أجيب حرفين كل واحد بـUnicode point مختلف، ولكن لما بيبقوا نصوص بيبقوا نفس الشكل بالظبط، بحيث أستخدمه في الخداع البصري!
الكمبيوتر يشوفهم مختلفين، ولكن العين تشوفهم واحد..
مثال:

في المثال اللي في الصورة دا، هتلاقي ع شمال الدومينات الصحيحة، وع يمين الدومينات الـfake اللي تم إنشائها من خلال استخدام حرف مُعين من اللغة اللاتينية مثلاً شبيه لنفس الحرف للغة الإنجليزية، والحرفين نفس الشكل، ولكن كل واحد فيهم بيكون له Unicode point مُختلف، بالتالي الكمبيوتر بيشوفهم حرفين مختلفين!
إيه هو الـ Homoglyphs؟
الـ Homoglyphs هي حروف أو رموز بتبان شبه بعض بصريًا بس ليها كود مختلف في النظام (زي Unicode). يعني بتشوف حرفين شبه بعض بالعين، بس الكمبيوتر بيعاملهم كحاجات مختلفة تمامًا. ده بيحصل لأن كل حرف في Unicode ليه Code Point معين، زي U+0061 للحرف اللاتيني a، وU+0430 للحرف السيريلي а.
أمثلة على Homoglyphs:
- الحرف اللاتيني
a(U+0061) vs. الحرف السيريليа(U+0430). - الحرف اللاتيني
o(U+006F) vs. الحرف اليونانيο(U+03BF). - الرقم
0(U+0030) vs. الحرفO(U+004F).
لو بصيت عليهم، هتحس إنهم نفس الحرف، بس الكمبيوتر بيشوفهم حاجات مختلفة.
إزاي بيُستخدموا في هجمات؟
الـ Homoglyphs بتُستخدم في هجمات زي الـ Visual Spoofing، وبالذات في الـ Phishing. يعني حد ممكن يعمل رابط ويب يبدو زي موقع حقيقي، لكن في الحقيقة هو مزيّف. مثلاً:
بدل ما تكتب apple.com، ممكن تستخدم الحرف السيريلي а عشان تخلّي الرابط يبقى xn--pple-43d.com. لو بصيت على الرابط بالعين، هتحس إنه apple.com بس هو فعليًا موقع تاني خالص.
مثال تاني:
رابط زي www.аррle.com (باستخدام а وр سيريلي) هيتحوّل لـ xn--pple-43d.com في المتصفح.
جرب كدا تنسخ الـlink دا وشوف هيتحوّل ازاي..
وطبعًا بيتم استخدام الـHomoglyphs لهجمات زي phishing أو تخطي الـfilters و WAFs ..
مثال عملي أخير:
لو عندك رابط زي: http://www.paypal.com ومحدش بص كويس، ممكن يتم استبدال الحرف a بحرف سيريلي а فالرابط يبقى: http://www.pаypal.com. الرابط ده هيوديك لموقع مزيّف ممكن يسرق بياناتك.
والـHomograph دا إيه هو؟
الـHomograph دا اللي بيكون كلمة بنكتب كلمة مختلفة عنها ولكن نفس شكلها كخداع بصري مش أكتر، زي موضوع microsoft هو rnicrosoft ..
تقدر تجرب تعمل homoglyph attack من خلال الموقع دا:
Homoglyph Attack Generator
بعض الـTechniques اللي معروفة اللي الكمبيوتر بيتعامل معاها بطريقة غريبة وبتساعدنا ننفذ الـAttacks بتاعتنا بسهولة::
لو كتبت
https://ⓨⓐⓢⓢⓔⓡ.com
هتتحوّل لـ https://yasser.com
ودا normalization بيقوم بيه المتصفح، وعشان تحول النص بالطريقة دي من خلال:
Font Changer
وهتلاحظ إن أغلب الـUnicode كلها المتصفح بيعملها normalization للشكل العادي للـASCII!

Web Server Encoding Charset
إزاي الويب سيرفر بيعرف يستخدم أنهي Encoding؟
في الويب، السيرفر والمتصفح لازم يتفقوا على طريقة عرض النصوص عشان الحروف زي العربي أو الإنجليزي أو حتى الإيموجي تظهر صح من غير ما تبوظ.
هنا بييجي دور Encoding مع بروتوكول HTTP. السيرفر بيستخدم طرق معينة عشان يقول للمتصفح: “بص، أنا ببعتلك النص بالـencoding ده مثلًا UTF-8”. لو الـencoding مش متحدّد صح، النصوص ممكن تظهر كنمط غريب زي العربية بدل اللغة العربية مثلاً.
ودلوقتي هنشرح إزاي السيرفر بيحدّد نوع الـencoding، سواء من إعدادات السيرفر نفسه أو من لغة البرمجة اللي مكتوب بيها الـweb application ..
إيه اللي بيحدّد الـencoding في الـweb application؟
السيرفر بيحدّد نوع الترميز عن طريق:
- HTTP Response Header
- HTML Meta Tag
- Server Configuration Settings
- Web application Technology
أولًا: الـHTTP Response Header
السيرفر بيبعت مع الـResponse معلومة بتقول للمتصفح إنه يستخدم encoding معين، زي المثال الأتي:
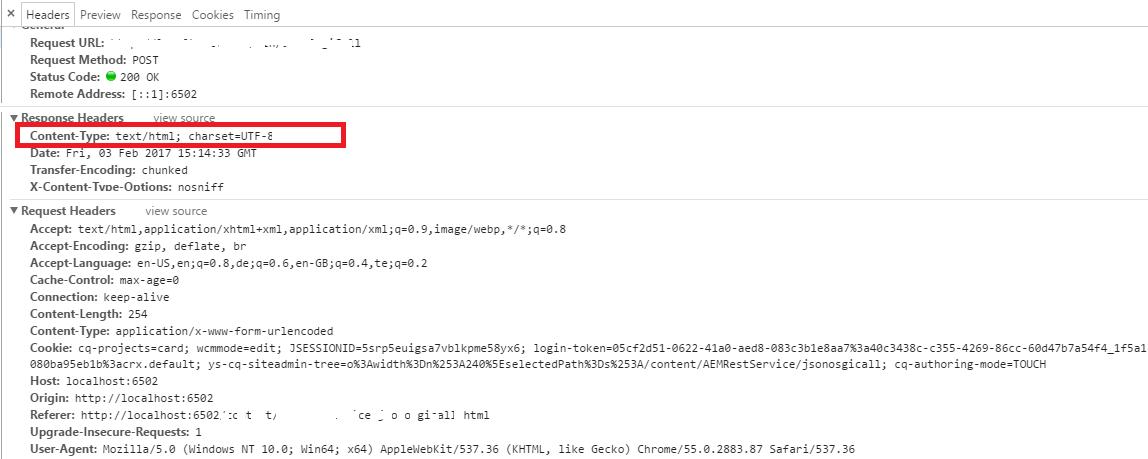
بروتوكول HTTP هو اللي بينظم التواصل بين السيرفر والمتصفح. لما السيرفر بيبعت صفحة ويب (Response)، بيضيف Header اسمه Content-Type بيحدّد نوع المحتوى بتاع الـresponse والـencoding المستخدم. وشكله بيبقى كدا:
Content-Type: text/html; charset=UTF-8
text/html: يعني المحتوى هو صفحة HTML.charset=UTF-8: يعني الترميز المستخدم هو UTF-8.
لو مفيش charset متحدّد، ساعتها الـbrowser ممكن يستخدم encoding افتراضي (زي ISO-8859-1)، وده بيسبب مشاكل لو النص عربي مثلًا ومش بيدعم كل اللغات!
وبالتالي هتلاقي النص العربي ظاهر عندك: مرØبًا بالعالم
ثانيًا: الـServer Configuration Settings
مثلاً لو الويب سيرفر Apache، تقدر تخليه يحدّد الـdefault encoding اللي هيتم استخدامه من خلال ملف .htaccess زي المثال التالي:
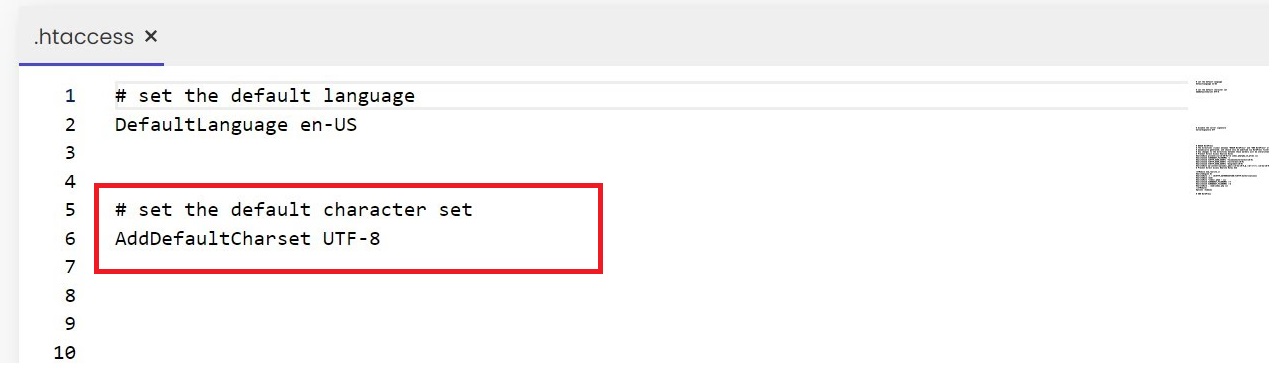
ده بيخلّي كل الـ Responses من السيرفر تستخدم UTF-8 افتراضيًا..
ثالثًا: الـWeb application Technology
لو بتستخدم لغة برمجة للـ Backend زي PHP مثلاً، بتقدر تتحكّم في الـEncoding من الكود نفسه اللي نت كاتبه!
- في PHP، بتستخدم function
header()عشان تحدّد الـ Content-Type:1 2 3 4
<?php header('Content-Type: text/html; charset=utf-8'); echo '<h1>اللهم صلي وسلم على أفضل الخلق سيدنا محمد</h1>'; ?>
- في Python Flask:
```python from flask import Flask, Response app = Flask(name)
@app.route(‘/’) def hello(): return Response(‘<h1>اللهم صلي وسلم على أفضل الخلق سيدنا محمد</h1>’, content_type=’text/html; charset=utf-8’)
if name == ‘main’: app.run()
1
2
3
4
5
6
7
8
9
10
11
12
13
#### رابعًا: الـHTML Meta tag
```html
<!DOCTYPE html>
<html lang="ar">
<head>
<meta charset="UTF-8">
<title>ElShabrawi Example</title>
</head>
<body>
<h1>اللهم صلي وسلم على أفضل الخلق سيدنا محمد</h1>
</body>
</html>
الـ <meta charset="UTF-8"> بيقول للمتصفح إن الصفحة بتستخدم UTF-8. لازم التاج ده يبقى في أول 1024 بايت من الصفحة عشان المتصفح يقراه صح.
طب أنا ليه بستخدم UTF-8 وأغلب الصفحات بـUTF-8؟
عشان بيدعم كل اللغات وكمان بيوفر مساحة عن UTF-16, UTF-32.
مشاكل لو الترميز مش متحدد صح
- النصوص ممكن تظهر بشكل عشوائي (زي
العربية). - لو فيه حروف زي Homoglyphs (حروف شبه بعض بصريًا)، ممكن تستخدم في هجمات Phishing.
الخلاصة اللي من الأخر:
تحديد الـencoding (زي UTF-8) هو مهم جدًا عشان النصوص تظهر صح، والسيرفر بيحدّد الـencoding عن طريق:
- HTTP Response Header: زي
Content-Type: text/html; charset=UTF-8. - إعدادات السيرفر: زي
AddDefaultCharset UTF-8في Apache. - لغة البرمجة: زي
header()في PHP. - HTML Meta Tag: زي
<meta charset="UTF-8">.
الخاتمة
الـ Encoding هو العمود الفقري يعتبر للتعامل مع النصوص في عالم الكمبيوتر.
من غير Encoding مظبوط زي UTF-8، النصوص ممكن تبوظ وتظهر بشكل غلط، وكمان ممكن تستغل في هجمات زي الـ Phishing باستخدام Homoglyphs (حروف شبه بعض بصريًا) أو Homographs (كلمات متشابهة في الكتابة).
بفضل الله وتوفيقه فهمنا إزاي أنواع الـEncoding زي URL Encoding، HTML Encoding، وBase64 بتساعدنا ننقل البيانات بأمان، وإزاي Unicode حلّ مشكلة دعم كل اللغات. كمان عرفنا إزاي السيرفر بيحدّد الـ Encoding عن طريق HTTP Headers، إعدادات السيرفر، أو لغات البرمجة زي PHP وPython.
لو أنت مبرمج، خلّي UTF-8 هو الـ Encoding الافتراضي، وتأكّد إنك بتحدده في الـ Headers والـ HTML عشان تحمي نفسك من أي مشاكل.
وأهم نصيحة: لو شفت رابط غريب، بص عليه كويس واستخدم أدوات زي Punycode Converter عشان تتأكّد إنه مش مزيّف. خلّيك دايما فايق يا معلم واصحى ليغفلونا. ♥
وفي النهاية، نشكر الله اللي علّمنا ما كنا نعلم، وندعوه يحفظنا ويحمينا من كل سوء،
“رَبِّ زِدْنِي عِلْمًا”، وإياكم.